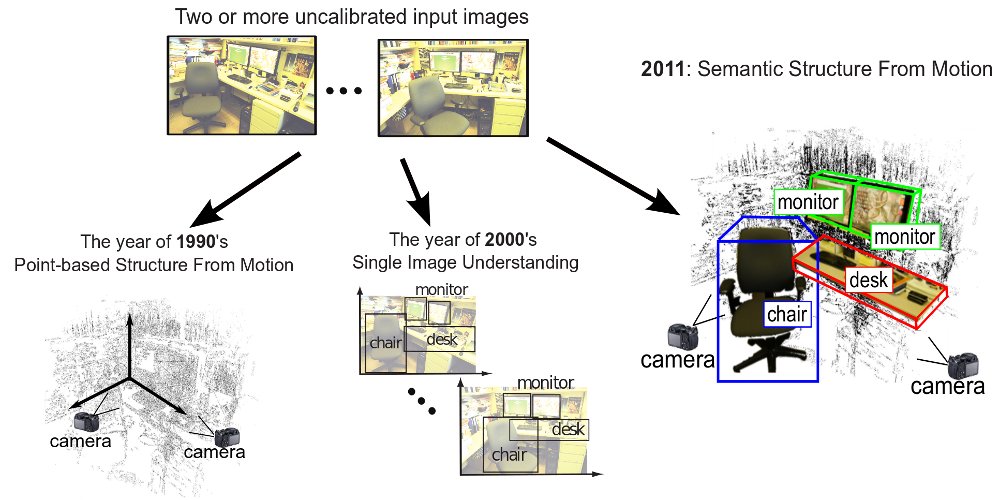
Traditional Structure from motion (SFM) aims at jointly recovering the
structure of a scene as a collection of 3D points and estimating the
camera poses from a number of input images. In this
project, called Semantic Structure from
Motion (SSFM) , we generalize this concept:
not only do we want to recover 3D points, but also recognize and
estimate the location of high level semantic scene components such as
regions and objects in 3D. As a key ingredient for this joint inference
problem, we seek to model various types of interactions between scene
components. Such interactions help regularize our solution and obtain
more accurate results than solving these problems in isolation.
Experiments on public datasets demonstrate that: 1) our framework
estimates camera poses more robustly
than SFM algorithms that use points only; 2) our framework is capable
of accurately estimating pose and location of objects, regions, and
points in the 3D scene; 3) our framework recognizes objects and regions
more accurately than state-of-the-art single image recognition
methods.
Check out our paper for details!
Update Jun 26, 2012
We presented our latest progress in the IEEE conference on
Computer Vision and Pattern Recognitoin 2012, Providence, RI. Please
check out our CVPR 12 paper for more details.
April, 2012
An extended version of our CVPR 2011 paper will be
published by Springer in a book "Outdoor and Large-Scale Real-World
Scene Analysis"
Dec 20, 2011
Our paper won the best student paper award in IEEE Workshop
on Challenges and Opportunities in Robot Perception!
Oct 20, 2011
Ford Car Dataset is updated. bugs in the 2D annotations are
fixed.
Oct 3, 2011
Ford Car Dataset is updated. The 3D point clouds are
included. The images are cropped to proper sizes. Object detector
models are included.
Sep 29, 2011
Kinect Dataset is updated. The list for testing pairs are
included. The object detector models for mouse, keyboard, bottle, cup,
monitor are included.
Sep 9, 2011
Kinect Dataset is uploaded! You could find 3D point clouds
aligned with 2D images.
Jun 19.2011
Detector model files of ford-car dataset are uploaded.
Jun. 7. 2011
The webpage is alive!
Source code version 0.1 is posted. This version might
contain bugs. Please email me and let's make the
software packege
better!
Car dataset is uploaded.
I will reply all related emails promptly.
Who might be
interested?
Researchers
who are interested in methods for 3D reconstruction from multiple
views, object detection and recognition, scene segmentation as well as
in applications such as autonomous navigation, robotics, object
manipulation and surveillance.
Papers and
citations
S. Yingze Bao, M. Bagra, Y. Chao, and
S. Savarese, Semantic
Structure from Motion with Points, Regions, and Objects, Proceedings of the IEEE International
Conference on Computer Vision and Pattern Recognition, 2012
download pdf
and bibtex
S. Yingze Bao and
S. Savarese, Semantic Structure from Motion: a Novel Framework for Joint Object Recognition and 3D Reconstruction, book chapter in "Outdoor and Large-Scale Real-World Scene Analysis", Springer, in press
download pdf
S. Yingze Bao and
S. Savarese, Semantic
Structure from Motion, Proceedings of the IEEE International
Conference on Computer Vision and Pattern Recognition, 2011
download pdf
(long version) and bibtex
S. Yingze Bao, M. Bagra, S. Savarese, Semantic Structure
From Motion with Object and Point Interactions, IEEE Workshop on
Challenges and Opportunities in Robot Perception (in conjunction with
ICCV-11)
download pdf
and bibtex.
Winner of the best student paper award
About us
Sid Yingze Bao is a 4th year PhD student in the Vision Lab at the University of Michigan, at Ann Arbor, EECS department
Silvio Savarese is an assistant professor of Electrical and Computer Engineering at U-M and director of the Vision Lab.
Results
Below
are 3 YouTube videos that illustrate the ability of SSFM to recover the
structure of a scene from multiple images and highlight the important
semantic phenomena. For more results please refer to our papers.
Video credits: Mohit Bagra
Soure code
June 7 2011, version 0.1 See README.txt for
installation. This code accompanies our CVPR 11 paper.
Data sets
Kinect
dataset (testing set) (version 0.2, date: Sep 29). See README.txt
in. Email the author
for obtaining training set. Object detector models are included.
Ford
Car Dataset (version 0.3, date: Oct 20). This dataset is a joint
effort of Pandey
et al. (for collecting images, Lidar points, calibration etc.) and us
(for annotation of 2D and 3D objects). So please cite both papers if
you appreciate the authors' effort.