 |
A Unified Framework for Multi-Target Tracking and Collective Activity Recognition
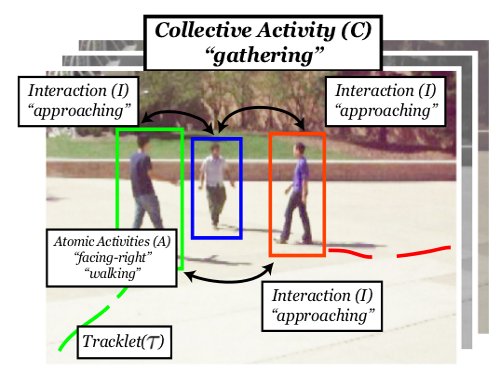
In this project we present a novel coherent, discriminative framework for simultaneously tracking multiple people and estimating their collective activities. Instead of treating these two problems separately, our model is grounded in the intuition that a strong correlation exists between a person's motion, their activity, and the motion and activities of other nearby people. We introduce a hierarchy of activity types that create a natural progression that leads from a specific person’s motion to the activity of the group as a whole. Experimental results on challenging video datasets demonstrate our theoretical claims and indicate that our model achieves the best collective activity classification results to date.
Check out our ECCV 2012 paper (selected as an oral presentation) and the project page. This project is in collaboration with Wongun Choi and is sponsored by ONR.
|
 |
Relating Things and Stuff via Object Property Interactions
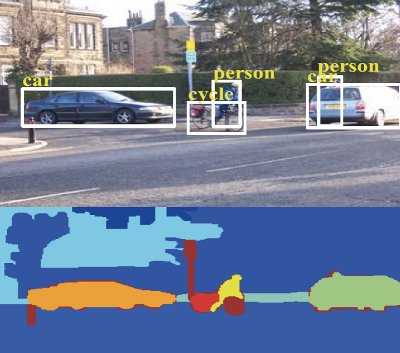
In this project we propose a new framework for scene understanding that jointly models things (i.e., object categories with a well-defined shape such as people and cars) and stuff (i.e., object categories with an amorphous spatial extent such as grass and sky). Our framework allows enforcing sophisticated geometric and semantic relationships between thing and stuff categories in a single graphical model. We demonstrate that our method achieves competitive performances in segmenting and detecting objects on several public datasets.
Check out our HitPot ECCV 2012 paper and the project page. This research is in collaboration with Byung Soo Kim, Min Sun and Pushmeet Kohli (Microsoft Research) and is sponsored by the Gigascale Systems Research Center and NSF CPS grant #0931474.
|
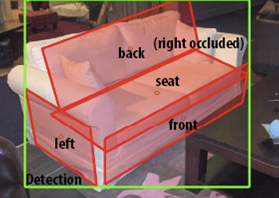 |
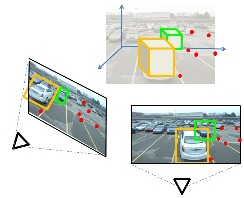
Estimating the Aspect Layout of Object Categories
In this project we seek to move away from the traditional paradigm for 2D object recognition whereby objects are identified in the image as 2D bounding boxes. We focus instead on: i) detecting objects; ii) identifying their 3D poses; iii) characterizing the geometrical and topological properties of the objects in terms of their aspect configurations in 3D.
Check out our CVPR 2012 paper and poster. The source code can be downloaded from here. This research is in collaboration with Yu Xiang and is sponsored by ARO W911NF-09-1-0310, NSF CPS grant #0931474 and a KLA-Tencor Fellowship.
|
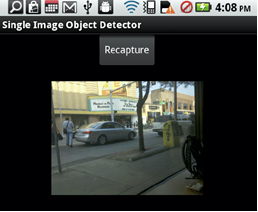 |
Mobile Object Detection through Client-Server based Vote Transfer
In this work we present a novel multi-frame object detection application for the mobile platform that is capable of object localization. We implement the multi-frame detector on a mobile device running the android OS through a novel client-server framework that presents a sound and viable environment for the multi-frame detector.
Check out our CVPR 2012 paper and poster. This research is in collaboration with Shyam Kumar and Min Sun and is sponsored by a Google Research Award and the Gigascale Systems Research Center.
|
 |
Efficient and Exact Branch-and-Bound
We propose a novel Branch-and-Bound (BB) method to efficiently solve exact MAP-MRF inference on problems with a large number of states (per variable). In our work, we evaluate different variants of our proposed BB algorithm and a state-of-the-art exact inference algorithm on synthetic data, human pose estimation from both a single image and a video sequence, and protein design problems.
Check out our AISTATS 2012 paper, our CVPR 2012 paper and poster. Source Code of the BB algorithm can be downloaded from here. This research is in collaboration with Prof. Honglak Lee and Prof. Silvio Savarese. It is sponsored by the ONR grant N000141110389, ARO grant W911NF-09-1-0310, and the Google Faculty Research Award.
|
 |
Semantic Structure from Motion (SSFM)
We propose a new framework for jointly recognizing objects as well as reconstructing the underlying 3D geometry of the scene (cameras, points and objects). In our SSFM framework we leverage the intuition that measurements of keypoints and objects must be semantically and geometrically consistent across view points. Our SSFM framework has the unique ability to: i) estimate camera poses from object detections only; ii) enhance camera pose estimation, compared to feature-point-based SFM algorithms; iii) improve object detections given multiple uncalibrated images, compared to independently detecting objects in single images.
Check out our CVPR 2012 paper and poster, our CVPR 2011 paper and poster, our book chapter, and our CORP-ICCV 2011 paper. Our CORP-ICCV 2011 paper is the winner of the best student paper. A newly proposed Microsoft KINECT dataset for evaluation can found here. In collaboration with Sid Ying-ze Bao. This research is sponsored by the Giga Scale Research Center and NSF CAREER #1054127.
|
 |
Joint Detection and Pose Estimation of Articulated Objects
In this project, we propose an new model called Articulated Part-based Model (APM) for jointly detecting objects (e.g humans) and estimating their poses (e.g. configuration of body parts such as arms, torso, head). APM recursively represents an object as a collection of parts at multiple levels of detail, from coarse-to-fine, where parts at every level are connected to a coarser level through a parent-child relationship. Extensive quantitative and qualitative experimental results on public datasets show that APM outperforms state-of-the-art methods.
In collaboration with Min Sun. Click here for our project webpage and the dataset. Check out our ICCV 2011 paper and poster. This research is sponsored by ARO.
|
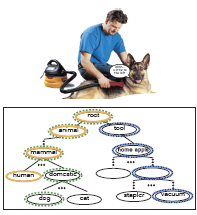 |
Hierarchical Classification of Images by Sparse Approximation
In this project we show that the hierarchical structure of a database can be used successfully to enhance classification accuracy using a sparse approximation framework. We propose a new formulation for sparse approximation where the goal is to discover the sparsest path within the hierarchical data structure that best represents the query object. Extensive quantitative and qualitative experimental evaluation on a number of subsets of the ImageNet database demonstrates our theoretical claims and shows that our approach produces better hierarchical categorization results than competing techniques.
Check out our BMVC 2011 paper and poster. In collaboration with Bying-Soo Kim, Jae Young Park, prof Anna Gilbert; Sponsored by a Google Research Award and the Gigascale Systems Research Center.
|
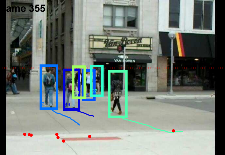 |
Multi-target tracking from a Single Moving Camera
We propose a coherent tracking framework which is capable of tracking multiple number of targets under unknown monocular camera motion. Our frameworks also models the interaction between targets which further helps disambiguate correspondence between targets and detections. To efficiently solve this complex inference problem, a MCMC particle filtering algorithm is incorporated. Experimental results show our algorithm is superior or comparable to the state-of-the-art multi-target system even though our algorithm only uses a single un-calibrated camera. We also tested our algorithm on a moving robotic platform equipped with a depth sensor and demonstrated higly accurate tracking capabilities.
Check out our ECCV 2010 paper and poster, our WCORP-ICCV 2012 paper. In collaboration with Wongun Choi and Caroline Pantofaru (Willow Garage). This research is sponsored by NSF-EAGER, TOYOTA and ONR.
|
 |
Monitoring with D4AR (4 Dimensional Augmented Reality) Models
In this research, construction progress deviations between as-planned and as-built construction are measured through superimposition of as-planned model onto site photographs for different time stamps. Our approach is based on sparse 3D reconstruction and recognition of as-built scene elements using state-of-the-art machine learning methodolgies.
Click here for our recent WCVRS-ICCV 2012 paper. For an earlier version please refer to our ITCON journal paper. This line of work won the best CRC poster award at the Construction Research Congress (Seattle 2009), the Best Student Paper Award at the The 6th Int. Conference on Innovation in AEC in 2010, and the 2012 Best Paper Award from the Journal of Construction Engineering and Management. In collaboration with Mani Golparvar-Fard and Feniosky Pena-Mora; Sponsored by NSF grant #0800500 and KLA-Tencor.
|
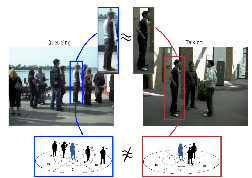 |
Collective Activities Recognition
We present a framework for the recognition of collective human activities. A collective activity is defined or reinforced by the existence of coherent behavior of individuals in time and space. We call such coherent behavior crowd context. Examples of collective activities are "queuing in a line" or "talking". We propose to recognize collective activities using the crowd context and introduce a new scheme for learning it automatically. Our scheme is constructed upon a Random Forest structure which randomly samples variable spatio-temporal regions to pick the most discriminating characteristics for classification.
Check out our CVPR 2011 paper and poster, our VSWS09 paper. Our dataset on collective activity classification can found here. In collaboration with Wongun Choi and Khuram Shahid. This research is sponsored by ONR and NSF EAGER.
|
 |
Human Actions Recognition by Attributes
We explore the idea of using high-level semantic concepts (attributes) to represent human actions from videos and argue that action attributes enable the construction of more descriptive models for human action recognition. We propose a unified framework wherein manually specified attributes are: i) selected in a discriminative fashion so as to account for intra-class variability; ii) integrated coherently with data-driven attributes to make the attribute set more descriptive.
Click here for our CVPR 2011 oral paper. In collaboration with Jingen Liu and Ben Kuipers. This research is sponsored by NSF #0931474.
|
 |
Cross-View Actions Recognition via View Knowledge Transfer
We present a novel approach for recognizing human actions from different views by establishing connections between view-dependent features across views (knowledge transfer). We introduce a novel approach for discovering these connections by using a bipartite graph to model view-dependent vocabularies of codewords. We then apply bipartite graph partitioning to co-cluster the vocabularies into visual-word clusters called bilingual-words (i.e., high-level features), which is capable of bridging the semantic gap between view-dependent vocabularies.
Click here for our CVPR 2011 oral paper. In collaboration with Jingen Liu, Mubarak Shah and Ben Kuipers. This research is sponsored by NSF #0931474.
|
 |
Depth-Encoded Hough Voting for Joint Object Detection and Shape Recovery
In this project we aim at simultaneously detecting objects, estimating their pose and recovering their 3D shape. We propose a new method called DEHV - Depth-Encoded Hough Voting. DEHV is a probabilistic Hough voting scheme which incorporates depth information into the process of learning distributions of image features (patches) representing an object category. Extensive quantitative and qualitative experimental analysis on existing and newly proposed datasets demonstrates that our approach achieves convincing recognition results and is capable of estimating object shape from just a single image!
Check out our ECCV 2010 paper and poster, and our DIM-PVT 2011 oral paper. Our Dataset (Released Sep,13,2010) is now available.
In collaboration with Min Sun, Gary Bradski, and Bing-Xin Xu. This research is sponsored by the Giga Scale Research Center and NSF grant #0931474.
|
 |
Coherent Object Recognition and Scene Layout Understanding
We propose a new coherent framework for joint object detection and scene 3D layout estimation from a single image. We explore the geometrical relationship among objects, the physical space includingthe objects and the observer. In our framework object detection becomes more and more accurate as additional evidence about a specific scene becomes available. In turn, improved detection results enable more stable and accurate estimates of the scene layout and object supporting surfaces.
Click here for the journal paper published in Image and Vision Computing, here for BMVC 10 oral, and here for the CVPR 10 paper (more details). Our Desk-top Dataset is now available. In collaboration with Sid Yingze Bao and Min Sun. This research is sponsored by the Giga Scale Research Center and NSF grant #0931474.
|
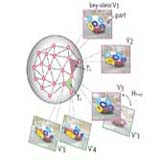 |
Learning a dense multi-view representation for detection, viewpoint classification and synthesis of object categories
We propose a new 3D object class model that is capable of recognizing unseen views by pose estimation and synthesis. We achieve this by using a dense, multiview representation of the viewing sphere parameterized by a triangular mesh of viewpoints. Each triangle of viewpoints can be morphed to synthesize new viewpoints. By incorporating 3D geometrical constraints, our model establishes explicit correspondences among object parts across viewpoints. Click here for our ICCV 09 oral; or here for the CVPR 09 version.
Details on our early work on multi-view object representation can be found in our ICCV 07 paper, or our ECCV 08 paper. Click here for our dataset on multi-view object categories. In collaboration with Min Sun, Hao Su, and Fei-Fei Li.
|
 |
Recognizing the 3D Pose of Object Categories by Manifold Modeling
We propose a novel statistical manifold modeling approach that is capable of classifying poses of object categories from video sequences by simultaneously minimizing the intra-class variability and maximizing inter-pose distance. We model an object category as a collection of non-parametric probability density functions (PDFs) capturing appearance and geometrical changes. We show that the problem of simultaneous intra-class variability minimization and inter-pose distance maximization is equivalent to the one of aligning and expanding the manifolds generated by these non-parametric PDFs, respectively.
Click here for our ICCV 2011 work and here for an earlier version (BMVC 09). In collaboration with Liang Mei, Jingen Liu and Alfred Hero; Sponsored by ARO Army and NSF grant #0931474.
|
 |
Scene categorization and understanding from videos
We present a new method for categorizing video sequences capturing different scene classes. This can be seen as a generalization of previous work on scene classification from single images. A scene is represented by a collection of 3D points with an appearance based codeword attached to each point. A hierarchical structure of histograms located at different locations and at different scales is used to capture the typical spatial distribution of 3D points and codewords in the working volume.
Click here for our ICCV 09 paper and here for the database. In collaboration with Paritosh Gupta, Sankalp Arrabolu and Matthew Brown.
|
 |
Perception of Reflective materials
How well can the human visual system see the shape of a reflective object? How does the brain identify a specular reflection as such and not as a piece of texture attached to the surface? Psychophysics analysis sheds light to these intriguing questions.
Click here for details. In collaboration with Andrey Del Pozo and Dan Simons; Sponsored by NSF grant #0413312.
|



